
Qwen开源首个长文本新模子,百万Tokens处感性能超GPT-4o-mini

金磊 整理自 凹非寺
量子位 | 公众号 QbitAI
谈到大模子的“国货之光”,除了DeepSeek以外,阿里云Qwen这边也有新动作——
初度将开源Qwen模子的险峻文膨大到1M长度。

具体而言,此次的新模子有两个“杯型”:
Qwen2.5-7B-Instruct-1MQwen2.5-14B-Instruct-1M它们在处理长文本任务中都仍是完好意思舒适超越GPT-4o-mini,况且在处理百万级别长文本输入时可完好意思近7倍的提速!
(百万Tokens长文本,如果换算来看的话,不错是10本长篇演义、150小时演讲稿或3万行代码。)

现在,Qwen新模子关连的推理框架和本领走漏等实践均仍是发布。
接下来,咱们就来不绝潜入了解一下。

模子性能
领先,让咱们来望望Qwen2.5-1M系列模子在长险峻文任务和随笔本任务中的性能进展。
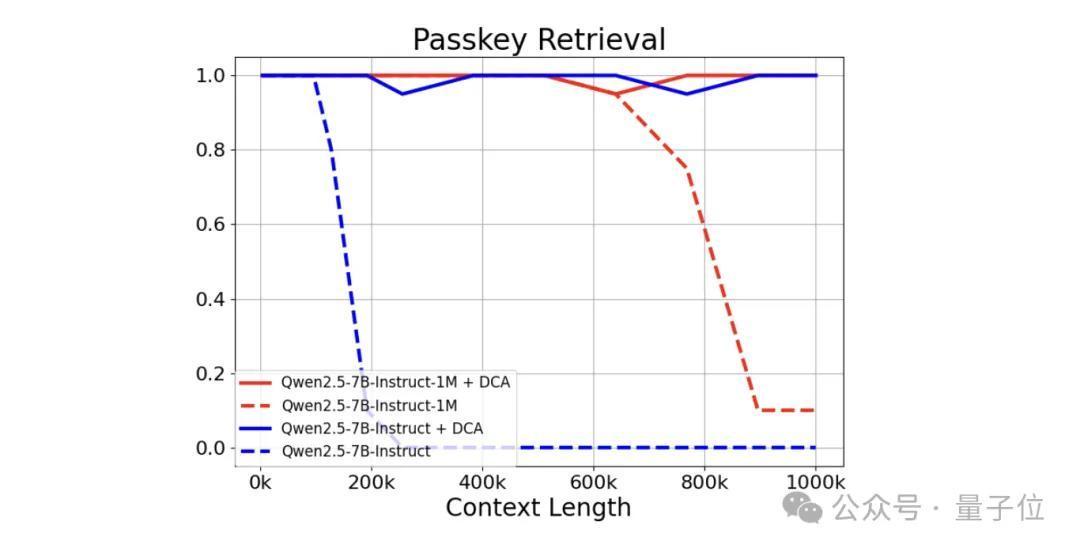
在险峻文长度高达 100万Tokens的 “大海捞针” 式任务 ——Passkey Retrieval(密钥检索)中,Qwen2.5-1M系列模子展现出不凡性能,好像精确地从长度为1M的文档里检索出荫庇信息。
值得一提的是,在总计系列模子中,仅7B模子出现了为数未几的不实。

关于更复杂的长险峻文理撤职务,参谋团队继承了RULER、LV-Eval和LongbenchChat等测试集。

详细这些效果来看,不错得到的枢纽论断如下:
一方面,Qwen2.5-1M系列模子比拟之前的128K版块有权臣跳动。
在多数长险峻文任务场景中,它进展更为出色,终点是应酬卓绝64K长度的任务时,好像更有用地处理信息,展现出相较于128K版块更强的稳当性与处理才气。
另一方面,Qwen2.5-14B-Instruct-1M模子具备一定上风。
在与Qwen2.5-Turbo以及GPT-4o-mini的对比中,该模子在多个数据集上的测评得益更为杰出。
这意味着,在现存的长险峻文模子可选畛域内,它算作开源模子,好像为使用者提供一种性能相对可靠、可替代其他居品的继承,不外不同模子都有各自的特色与适用场景,仍需依据具体需求进行判断。
除了长序列任务的性能外,咱们相通关怀这些模子在短序列上的进展。
团队在平凡使用的学术基准测试中比较了Qwen2.5-1M系列模子及之前的128K版块,并加入了GPT-4o-mini进行对比。

由此不错发现:
Qwen2.5-7B-Instruct-1M和Qwen2.5-14B-Instruct-1M在随笔本任务上的进展与其128K版块十分,确保了基本才气莫得因为增多了长序列处理才气而受到影响。与GPT-4o-mini比拟,Qwen2.5-14B-Instruct-1M和Qwen2.5-Turbo在随笔本任务上完好意思了周边的性能,同期险峻文长度是GPT-4o-mini的八倍。奈何真金不怕火成的?在先容完性能之后,咱们来看下Qwen新模子背后的枢纽本领。
主要不错分为三大门径,它们分辩是长险峻文磨练、长度外推和稀零珍眼力机制。

长序列的磨练需要精深的野心资源,因此团队采用了迟缓膨大长度的步调,在多个阶段将Qwen2.5-1M的险峻文长度从4K膨大到256K:
团队从预磨练的Qwen2.5的一个中间查验点运转,此时险峻文长度为4K。在预磨练阶段,团队迟缓将险峻文长度从4K增多到256K,同期使用Adjusted Base Frequency的有谋略,将RoPE基础频率从10,000提高到10,000,000。在监督微调阶段,团队分两个阶段进行以保握短序列上的性能:* 第一阶段:仅在短辅导(最多32K长度)上进行微调,这里咱们使用与Qwen2.5的128K版块调换的数据和门径数,以得到近似的短任务性能。
第二阶段:羼杂短辅导(最多32K)和长辅导(最多256K)进行磨练,以完好意思在增强长任务的性能的同期,保握短任务上的准确率。在强化学习阶段,团队在随笔本(最多8K长度)上磨练模子。团队发现,即使在随笔本上进行磨练,也能很好地将东谈主类偏好对皆性能泛化到长险峻文任务中。
通过以上磨练,最终得到了256K险峻文长度的辅导微调模子。

在上述磨练流程中,模子的险峻文长度仅为256K个Tokens。为了将其膨大到1M ,团队采用了长度外推的本领。
现时,基于旋转位置编码的大型讲话模子会在长险峻文任务中产素性能着落,这主若是由于在野心珍眼力权重时,Query和Key之间的相对位置距离过大,在磨练流程中未尝见过。
为了管制这一问题,团队引入了Dual Chunk Attention (DCA),该步调通过将过大的相对位置,重新映射为较小的值,从而管制了这一困难。
效果标明,即使是仅在32K长度上磨练的Qwen2.5-7B-Instruct,在处理1M险峻文的Passkey Retrieval任务中也能达到近乎齐备的准确率。
这充分展示了DCA在无需特等磨练的情况下,也可权臣膨大援手的险峻文长度的巨大才气。
临了,就是稀零珍眼力机制。
关于长险峻文的讲话模子,推理速率对用户体验至关迫切。为为此,团队引入了基于MInference的稀零珍眼力优化。
在此基础上,参谋东谈主员还建议了一系列改造:包括分块预填充、集成长度外推有谋略、稀零性优化等。
通过这些改造,团队的推理框架在不同模子大小和GPU竖立上,处理1M长度输入序列的预填充速率升迁了3.2倍到6.7倍。
临了,该形势仍是提供了在线体验的地址,感兴趣兴趣的小伙伴不错去尝鲜了~
HuggingFace体验地址:
https://huggingface.co/spaces/Qwen/Qwen2.5-1M-Demo魔塔社区体验地址:
https://www.modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo本领走漏:
https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf参考承接:
https://qwenlm.github.io/zh/blog/qwen2.5-1m/— 完 —
量子位 QbitAI · 头条号签约
关怀咱们,第一时刻获知前沿科技动态