
4o-mini只好8B,o1也才300B!微软论文无意曝光GPT中枢机密

微软又把OpenAI的机密流露了??在论文中后堂堂写着:
o1-preview约300B参数,GPT-4o约200B,GPT-4o-mini约8B……

英伟达2024年头发布B200时,就摊牌了GPT-4是1.8T MoE也等于1800B,这里微软的数字更精准,为1.76T。

除此以外,论文中给OpenAI的mini系列,Claude3.5 Sonnet也齐附上了参数,归来如下:
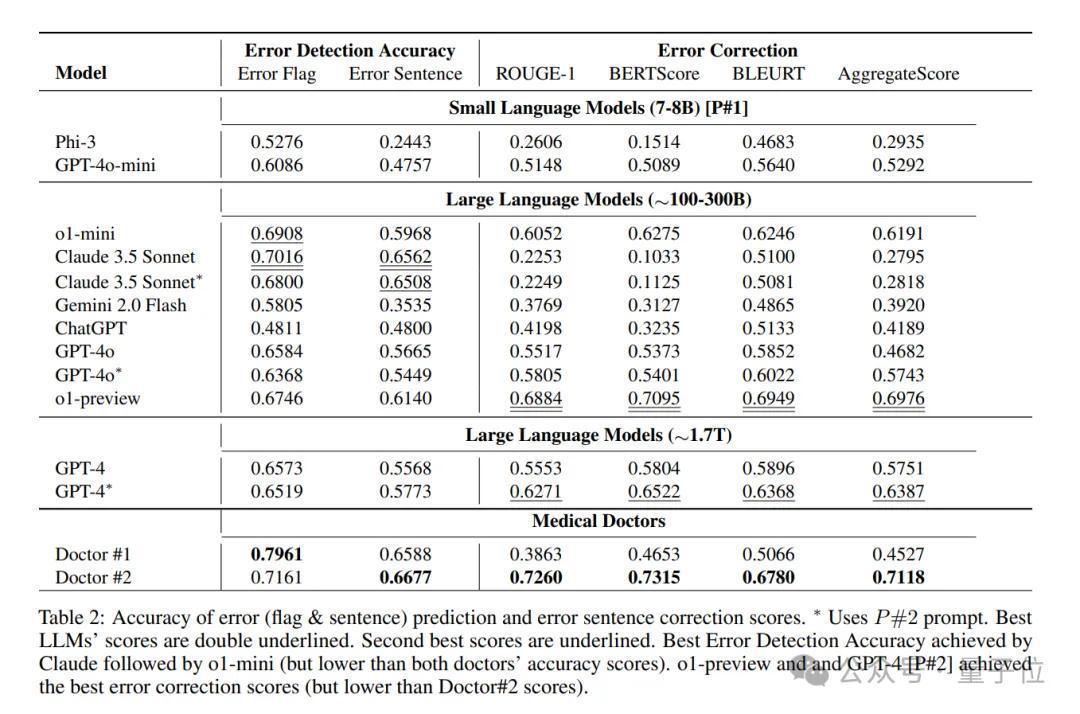
o1-preview约300B;o1-mini约100BGPT-4o约200B;GPT-4o-mini约8BClaude 3.5 Sonnet 2024-10-22版块约175B微软我方的Phi-3-7B,这个无谓约了等于7B天然论文中背面也有免责声明:
的确数据尚未公开,这里大部分数字是估量的。

但如故有不少东说念主以为事情没这样浅近。
比如为什么唯一莫得放谷歌Gemini模子的参数估量?偶而他们对放出来的数字如故有信心的。
也有东说念主认为,大多量模子齐是在英伟达GPU上启动的,是以不错通过token生成速率来估量。
只好谷歌模子是在TPU上启动的,是以不好估量。
况且微软也不是第一次干这事了。
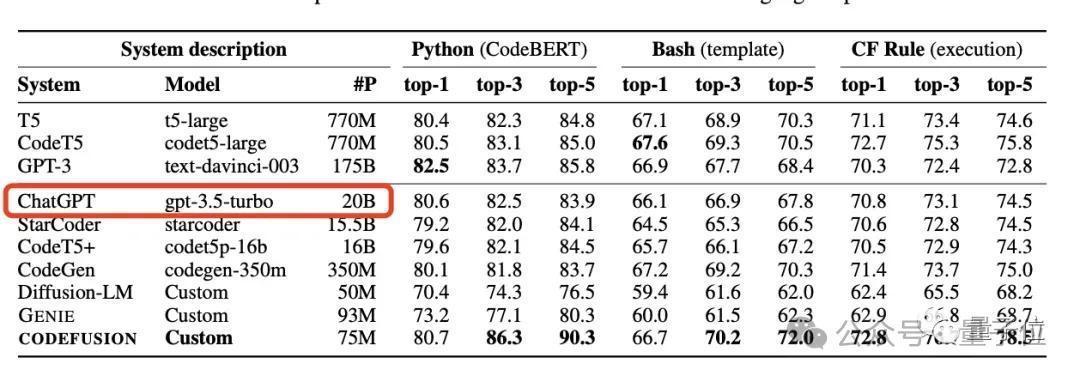
23年10月,微软就在一篇论文里“无意”曝出GPT-3.5-Turbo模子的20B参数,在后续论文版块中又删除了这一信息。
就说你是迥殊的如故不防卫的?

微软这篇论文说了什么
履行上,原论文先容了一项与医学干系的benchmark——MEDEC。
12月26日就仍是发布,不外是比拟垂直领域的论文,可能非干系标的的东说念主齐不会看,年后才被列灯谜克网友们发现。

有计划缘故是,据好意思国医疗机构访问败露,有1/5的患者在阅读临床札记时论说发现了颠倒,而40%的患者认为这些颠倒可能影响他们的治愈。
况且另一方面,LLMs(大讲话模子)被越来越多的用于医学文档任务(如生成诊疗活动)。
因此,MEDEC此番有两个任务。一是识别并发现临床札记中的颠倒;二是还能给以改正。
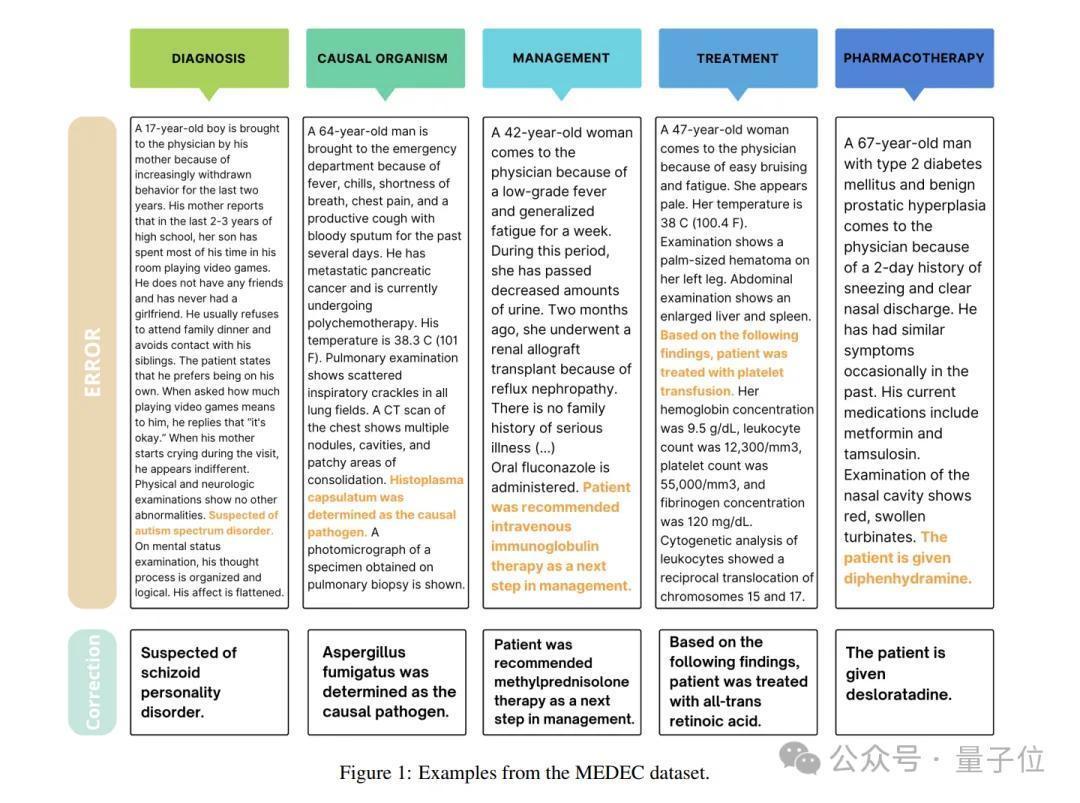
为了进行有计划,MEDEC数据集包含3848份临床文本,其中包括来自三个好意思国病院系统的488份临床札记,这些札记之前未被任何LLM见过。
它涵盖五种类型的颠倒(会诊、贬责、治愈、药物治愈和致病因子),这些颠倒类型是通过分析医学委员会教师中最常见的问题类型领受的,并由8位医疗东说念主员参与颠倒标注。
而参数流露即发生在实验法子。
按确乎验蓄意,有计划者将收用近期主流的大模子和小模子来参与札记识别和纠错。
而就在先容最终选用的模子时,模子参数、发布时代一下子齐被公开了。

对了,省去中间经由,这项有计划得出的论断是:Claude 3.5 Sonnet在颠倒标记检测方面优于其他LLM活动,得分为70.16,第二名是o1-mini。
网友:按价钱算合理
每一次,ChatGPT干系模子架构和参数流露,齐会引起山地风云,此次也不例外。
23年10月,微软论文宣称GPT-3.5-Turbo只好20B参数的时候,就有东说念主惊奇:难怪OpenAI对开源模子这样弥留。
24年3月,英伟达证据GPT-4是1.8T MoE,而2000张B200不错在90天内完成教师的时候,天下以为MoE仍是且仍将是大模子架构趋势。

这一次,基于微软估量的数据,网友们主要有几个关心点:
如若Claude 3.5 Sonnet确凿比GPT-4o还小, 那Anthropic团队就领有本领上风。
以及不战胜GPT-4o-mini只好8B这样小。

不外此前也有东说念主凭证推理资原本算,4o-mini的价钱是3.5-turbo的40%,如若3.5-turbo的20B数字准确,那么4o-mini刚好是8B附近。
不外这里的8B亦然指MoE模子的激活参数。
总之,OpenAI好像是不会公布的确数字了。
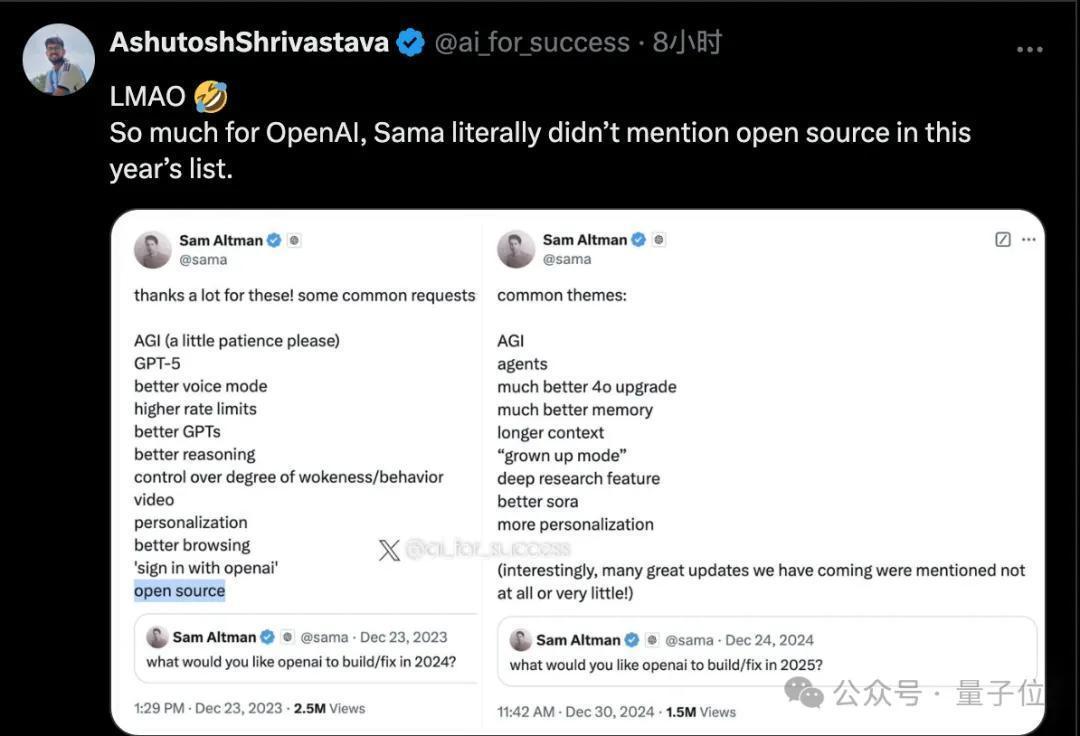
此前奥特曼搜集2024年新年愿望,临了公布的清单中还有“开源”。2025年的最新版块里,开源仍是被去掉了。
论文地址:
https://arxiv.org/pdf/2412.19260