
北掀开源首个针对视频编著的新所在,与东说念主类感知高度对皆|AAAI25

视频生成模子卷得热气腾腾,配套的视频评价范例当然也不可过时。
当今,北京大学MMCAL团队建造了首个用于视频编著质地评估的新所在——VE-Bench,联系代码与预锻练权重均已开源。
它要点关心了AI视频编著中最常见的一个场景:视频编著前后收尾与原始视频之间的辩论。
举例,在“摘掉女孩的耳饰”的任务中,需要保留东说念主物ID,源视频与编著收尾应该有着较强语义联系性,而在“把女孩换为钢铁侠”这么的任务中,语义就赫然发生了更正。
此外,它的数据还愈加安妥东说念主类的主不雅感受,是一个有用的主不雅对皆量化所在。
实际收尾流露,与FastVQA、StableVQA、DOVER、VE-Bench QA等视频质地评价措施比拟,VE-Bench QA得回了SOTA的东说念主类感知对皆收尾:
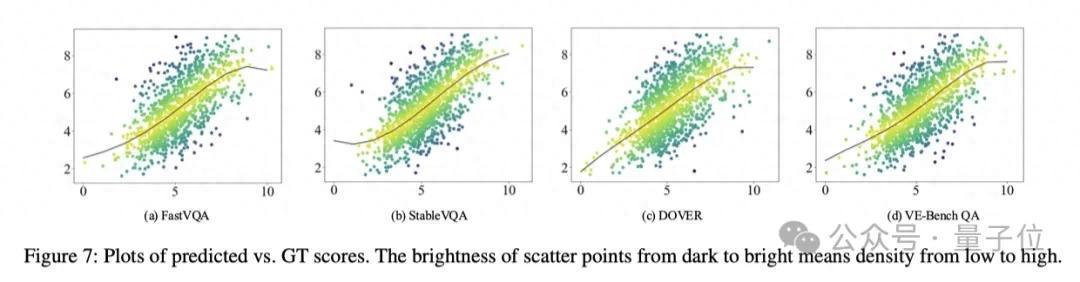
这到底是奈何作念到的呢?
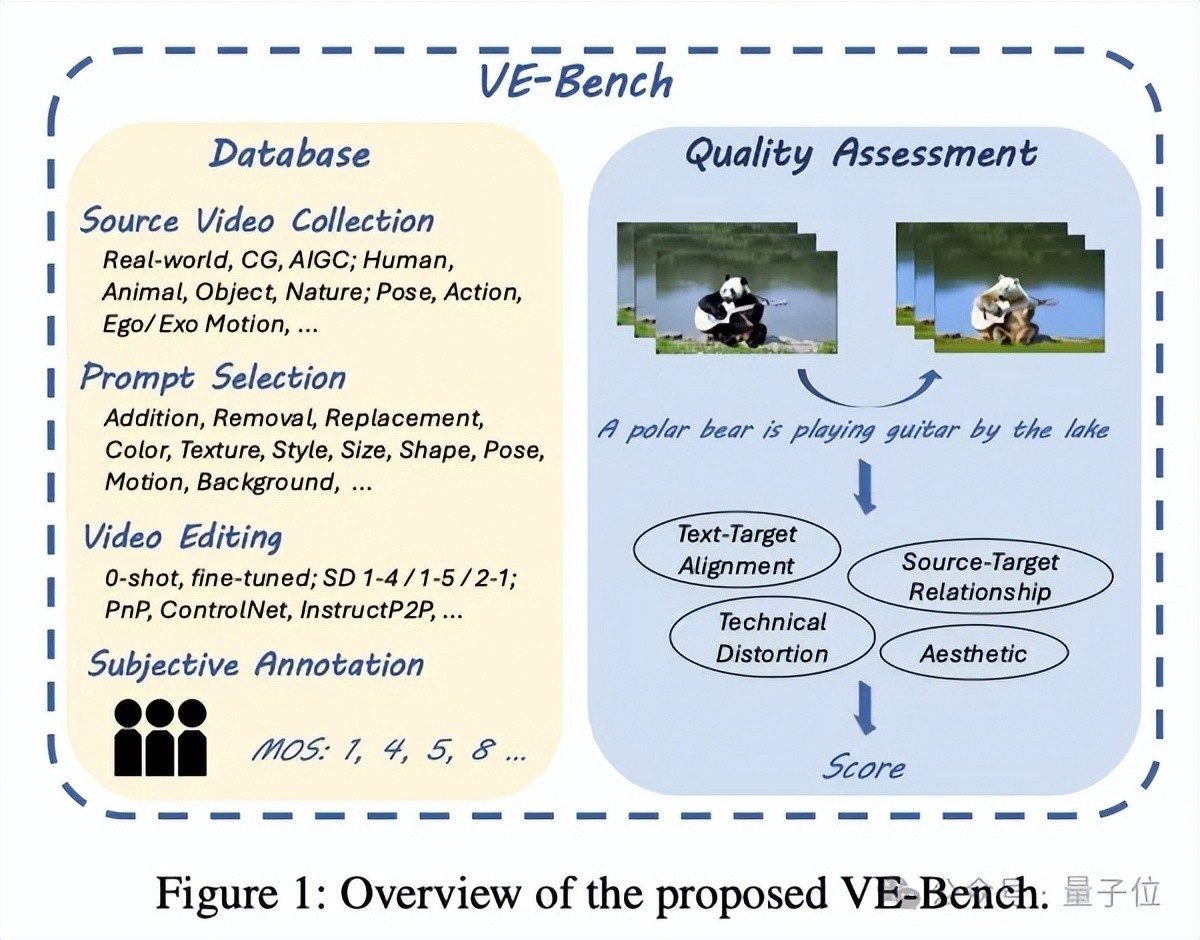
简便来说,VE-Bench最初从原始视频网罗、教唆词网罗、视频编著措施、主不雅标注4个方面脱手,构建了一个愈加丰富的数据库VE-Bench DB。
此外,团队还忽视了立异的测试措施VE-Bench QA,将视频的举座效果分红了翰墨-所在一致性、参考源与所在的关系、工夫畸变和好意思学范例多个维度进行抽象评价,比现常常用的CLIP分数等客不雅所在、PickScore等反应东说念主类偏好的所在都愈加全面。
联系论文已入选AAAI 2025(The Association for the Advancement of Artificial Intelligence)会议。

更丰富全面的数据库VE-Bench DB原始视频网罗
为了确保数据各样性,VE-Bench DB除了网罗来自信得过全国场景的视频,还包括CG渲染的骨子以及基于文本生成的AIGC视频。
数据起首包括公开数据集DAVIS、Kinetics-700、Sintel、Spring的视频,来自Sora和可灵的AIGC视频,以及来自互联网的补充视频。
来自互联网的视频包括极光、熔岩等老例数据集枯竭的场景。
扫数视频都被转机为长边768像素,同期保抓其原始宽高比。
由于面前主流视频编著措施守旧的长度戒指,每段视频都被剪辑为32帧。
源视频的具体骨子组成如下图所示,扫数样本在网罗时均通过东说念主工筛选以保证骨子的各样性并减少冗余:

△VE-Bench原始视频组成。(a)视频起首 (b)视频类型 (c) 视频畅通种类 (d) 视频骨子种类教唆词网罗
参考过往使命,VE-Bench将用于编著的教唆词分为3大类别:
立场编著(Style editing):包括对心思、纹理或举座氛围的编著。语义编著(Semantic editing):包括配景编著和局部编著,举例对某一双象的添加、替换或移除。结构编著(Structural editing):包括对象大小、姿态、四肢等的变化。针对每个类别,团队东说念主工编写了相应的教唆词,对应的词云与类别组成如下:

△VE-Bench教唆词组成。(a)词云 (b)教唆词类型占比统计编著收尾生成
VE-Bench选取了8种视频编著措施。
这些措施包括早期的经典措施与近期较新的措施,涵盖从SD1.4~SD2.1的不同版块,包括需要微调的措施、0-shot的措施、和基于ControlNet、PnP等不同战术编著的措施。
东说念主类主不雅评价在进行主不雅实际时,VE-Bench确保了每个视频样本均由24位受试者进行打分,安妥ITU范例中15东说念主以上的东说念主数条目。
所参与受试者均在18岁以上,学历均在本科及以上,包括商学、工学、理学、法学等不同的配景,有孤苦的判断武艺。
在实际驱动前,扫数东说念主会线下集合进行培训,而且会展示数据集以外的不同猛烈的编著例子。
测试时,受试者被条目阐述其主不雅感受,并对以下几个方面进行抽象评价:文本与视频的一致性、源视频与所在视频的联系度以及编著后视频的质地,分数为相称制。
临了网罗得到的不同模子平均得分的箱线图如下:
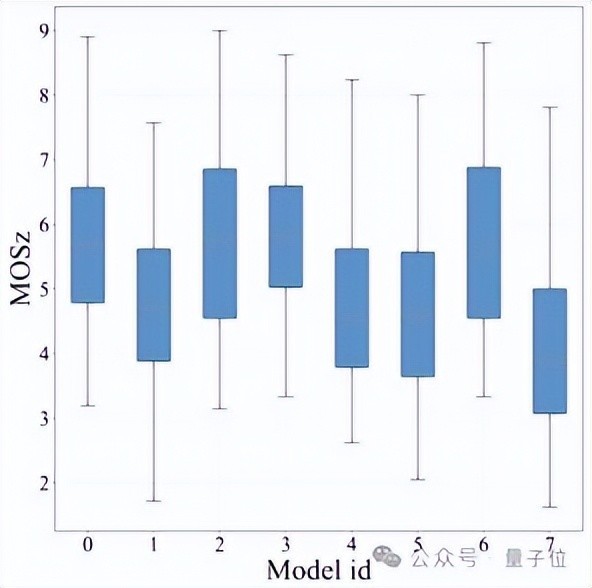
△VE-Bench模子得分箱线图
其中,横坐标示意不同模子ID,纵坐标示意Z-score正则化后的MOS (Mean Opinion Score)分数。橘红色线条示意得分的中位数。
不错看出,现时的大多数文本驱动的视频编著模子中位数得分广大在5分控制浮动,少数模子的得分中位数不错达到近6分,部分模子的得分中位数不到4分。
模子得分最低分不错下探到不到2分,也有个别样本最高不错达到近9分。
具体每个样本在Z-score前后的得分直方图如下图所示,不错看出极高分和极低分仍在少数:
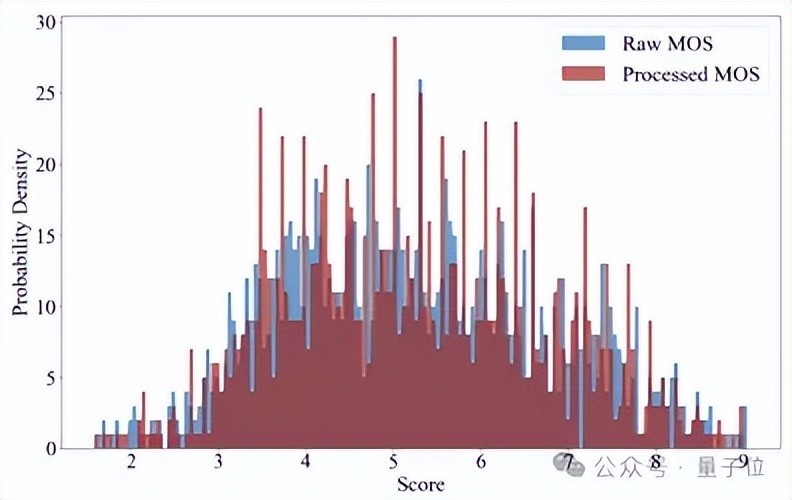
△VE-Bench模子得分直方图
在此基础上,团队进一步绘图了不同视频编著模子在VE-Bench教唆词上的表现:
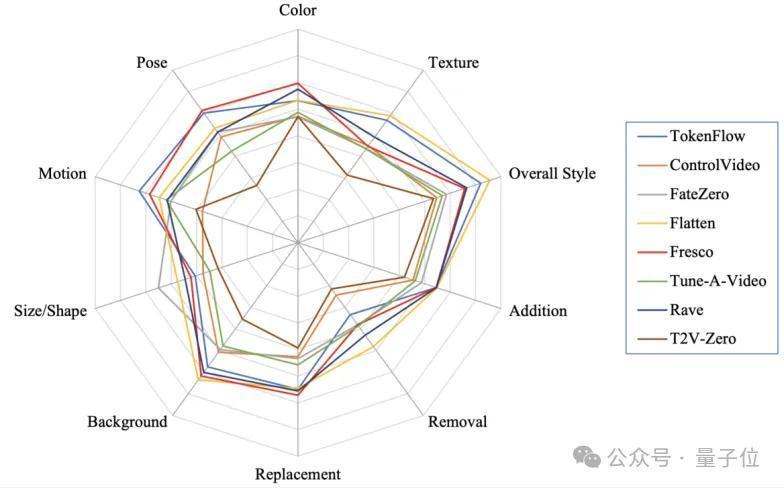
△不同视频编著模子在VE-Bench中不同类别的教唆词上的表现
不错看出,面前的模子都相对较为擅长立场化指示,这可能是诓骗了SD在广大不同立场图片上锻练的先验效果。
同期,删除指示比拟于添加得分更低,因为它需要特等辩论物体或配景重建等问题,对模子语义领路与细粒度特征索求武艺有更高条目。
现存模子都还不太擅长情景编著。这方面FateZero模子表现较为优秀,这可能与它针对shape-aware忽视的贯注力搀杂措施辩论。
从3个纬度进行评估的VE-Bench QA在构建的VE-Bench DB的基础上,团队还忽视了立异的VE-Bench QA锻练措施,所在是得到与东说念主类感知愈加接近的分数。
底下这张图展示了VE-Bench QA的主要框架:
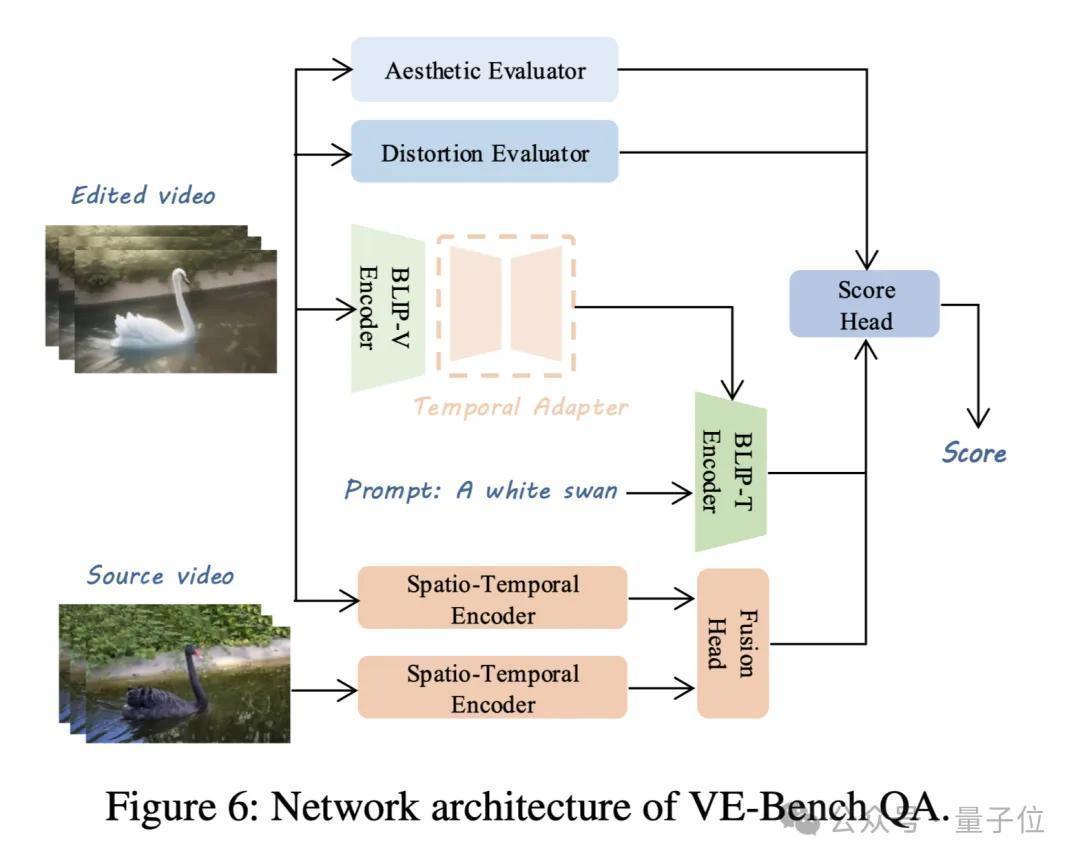
VE-Bench QA从3个维度对文本驱动的视频编著进行评估:
文本-视频一致性为了揣度所编著视频是否与文本辩论,VE-Bench QA基于BLIP进行了有用的视频-文本联系性建模,通过在BLIP视觉分支的基础上加入Temporal Adapter将其扩张到三维,并与文天职支的收尾通过交叉贯注力得到输出。
源视频-编著后视频动态联系性为了更好建模随凹凸文动态变化的联系性关系,VE-Bench QA在该分支上通过时空Transformer将二者投影到高维空间,并在此基础上拼接后诓骗贯注力机制揣摸二者联系性,临了通过转头揣摸得到相应输出。
传统维度的视觉质地方面VE-Bench QA参考了过往当然场景视频质地评价的优秀使命DOVER,通过在好意思学和失真方面预锻练事后的主干汇注输出相应收尾。
最终各个分支的输出通过线性层转头得到最终分数。
实际收尾流露,VE-Bench QA在多个数据集上所预计的收尾,其与真值的联系性得分都超过于其他措施:
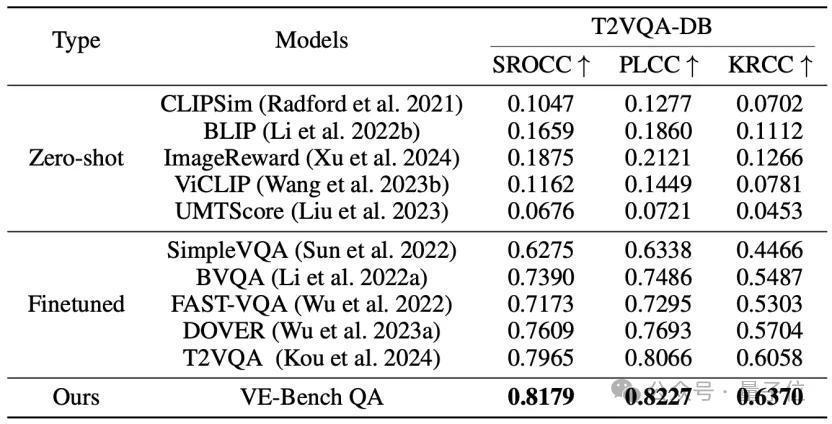
△VE-BenchQA在T2VQA-DB数据集上的收尾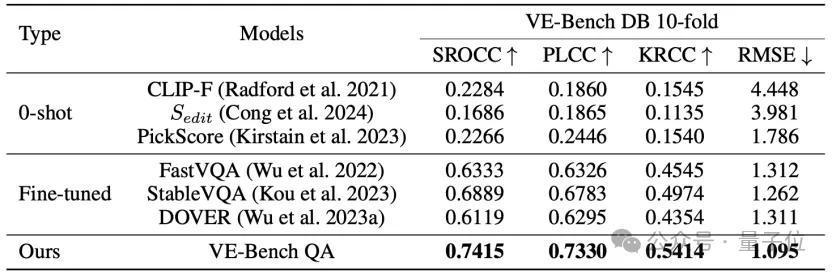
△VE-Bench QA在VE-Bench DB数据集上的收尾
论文集合:https://arxiv.org/abs/2408.11481代码集合:https://github.com/littlespray/VE-Bench
— 完 —
量子位 QbitAI · 头条号签约
关心咱们,第一时间获知前沿科技动态