
GPT-4o加钱能变快!新功能7秒完成原先23秒的任务

金磊 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI出了个新功能,径直让ChatGPT输出的速率原地升空!
这个功能叫作念“算计输出”(Predicted Outputs),在它的加执之下,GPT-4o不错比原先快至多5倍。
以编程为例,来感受一下这个feel:
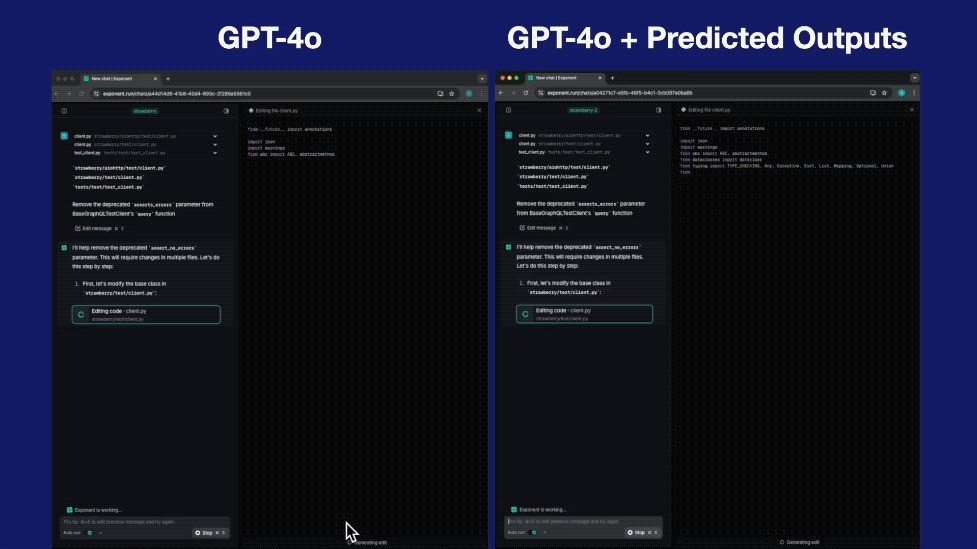
为啥会这样快?用一句话往复首即是:
跳过已知推行,不必从新初始从重生成。
因此,“算计输出”就相配稳妥底下这些任务:
在文档中更新博客著述迭代先前的反馈重写现存文献中的代码而且与OpenAI互助建造这个功能的FactoryAI,也亮出了他们在编程任务上的数据:

从实验效果来看,“算计输出”加执下的GPT-4o反馈时候比之前快了2-4倍,同期保执高精度。
况兼官方还示意:
原先需要70秒完成的编程任务,目下只需要20秒。
值得刺主见是,目下“算计输出”功能仅接济GPT-4o和GPT-4o mini两个模子,且所以API的体式。
关于建造者而言,这不错说是个利好音问了。
网友们在线实测音问一出,广博网友亦然坐不住了,反手即是实测一波。
举例Firecrawl独创东说念主Eric Ciarla就用“算计输出”体验了一把将博客著述转为SEO(搜索引擎优化)的推行,然后他示意:
速率确凿超等快。
它就像在API调用中添加一个算计参数同样简便。
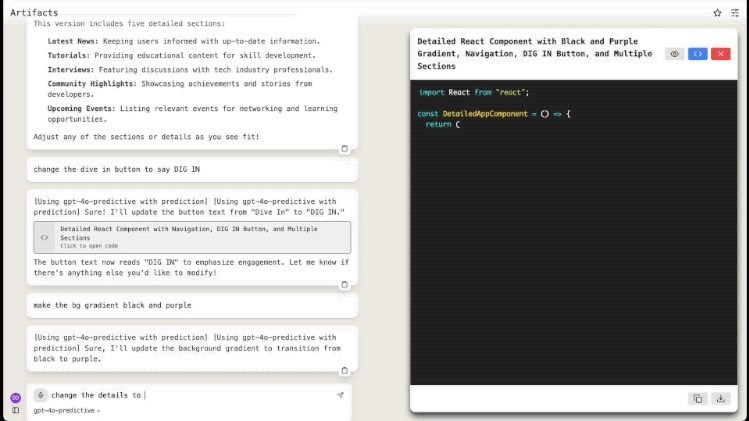
另一位网友则是在已有的代码之上,“喂”了一句Prompt:
change the details to be random pieces of text.
将详备信息革新为迅速文本片断。来感受一下这个速率:
也有网友晒出了我方实测的数据:
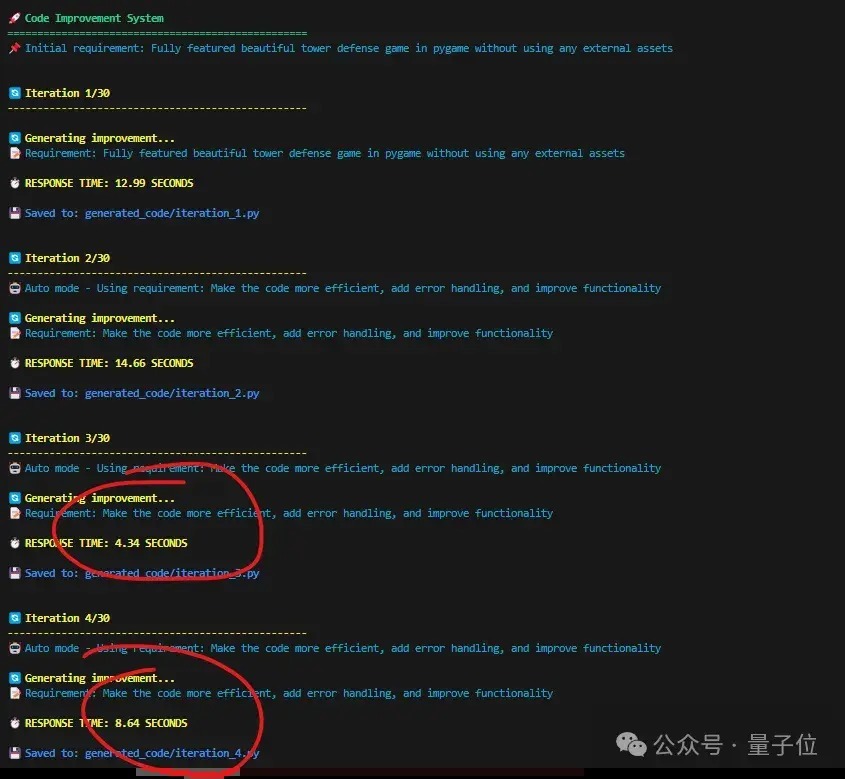
一言以蔽之,快,是确凿快。
若何作念到的?关于“算计输出”的时间细节,OpenAI在官方文档中也有所先容。

OpenAI合计,在某些情况下,LLM的大部分输出齐是提前知说念的。
淌若你条目模子仅对某些文本或代码进行隐微修改,就不错通过“算计输出”,将现存推行动作算计输入,让延长赫然缩小。
举例,假定你念念重构一段 C# 代码,将 Username 属性革新为 Email :
/// <summary>/// Represents a user with a first name, last name, and username./// </summary>public class User{ /// <summary> /// Gets or sets the user's first name. /// </summary> public string FirstName { get; set; } /// <summary> /// Gets or sets the user's last name. /// </summary> public string LastName { get; set; } /// <summary> /// Gets or sets the user's username. /// </summary> public string Username { get; set; }}你不错合理地假定文献的大部安分容将不会被修改(举例类的文档字符串、一些现存的属性等)。
通过将现存的类文献动作算计文本传入,你不错更快地从重生成扫数这个词文献。
import OpenAI from "openai";const code = `/// <summary>/// Represents a user with a first name, last name, and username./// </summary>public class User{ /// <summary> /// Gets or sets the user's first name. /// </summary> public string FirstName { get; set; } /// <summary> /// Gets or sets the user's last name. /// </summary> public string LastName { get; set; } /// <summary> /// Gets or sets the user's username. /// </summary> public string Username { get; set; }}`;const openai = ew OpenAI();const completion = await openai.chat.completions.create({ model: "gpt-4o", messages: [ { role: "user", content: "Replace the Username property with an Email property. Respond only with code, and with no markdown formatting." }, { role: "user", content: code } ], prediction: { type: "content", content: code }});// Inspect returned dataconsole.log(completion);使用“算计输出”生成tokens会大大缩小这些类型苦求的延长。
不外关于“算计输出”的使用,OpenAI官方也给出了几点刺目事项。
率先即是咱们刚才提到的仅接济GPT-4o和GPT-4o-mini系列模子。
其次,以下API参数在使用算计输出时是不受接济的:
values greater than 1logprobspresence_penalty greater than 0frequency_penalty greater than 0audio optionsmodalities other than textmax_completion_tokenstools - function calling is not supported除此以外,在这份文档中,OpenAI还回想了除“算计输出”以外的几个延长优化的步地。
包括“加快搞定token”、“生成更少的token”、“使用更少的输入token”、“减少苦求”、“并行化”等等。
文档辘集放在文末了,感好奇的小伙伴不错查阅哦~
One More Thing固然输出的速率变快了,但OpenAI还有一个刺目事项激励了网友们的探究:
When providing a prediction, any tokens provided that are not part of the final completion are charged at completion token rates.
在提供算计时,所提供的任何非最终完成部分的tokens齐按完成tokens费率收费。有网友也晒出了他的测试效果:
未汲取“算计输出”:5.2秒,0.1555好意思分汲取了“算计输出”:3.3秒,0.2675好意思分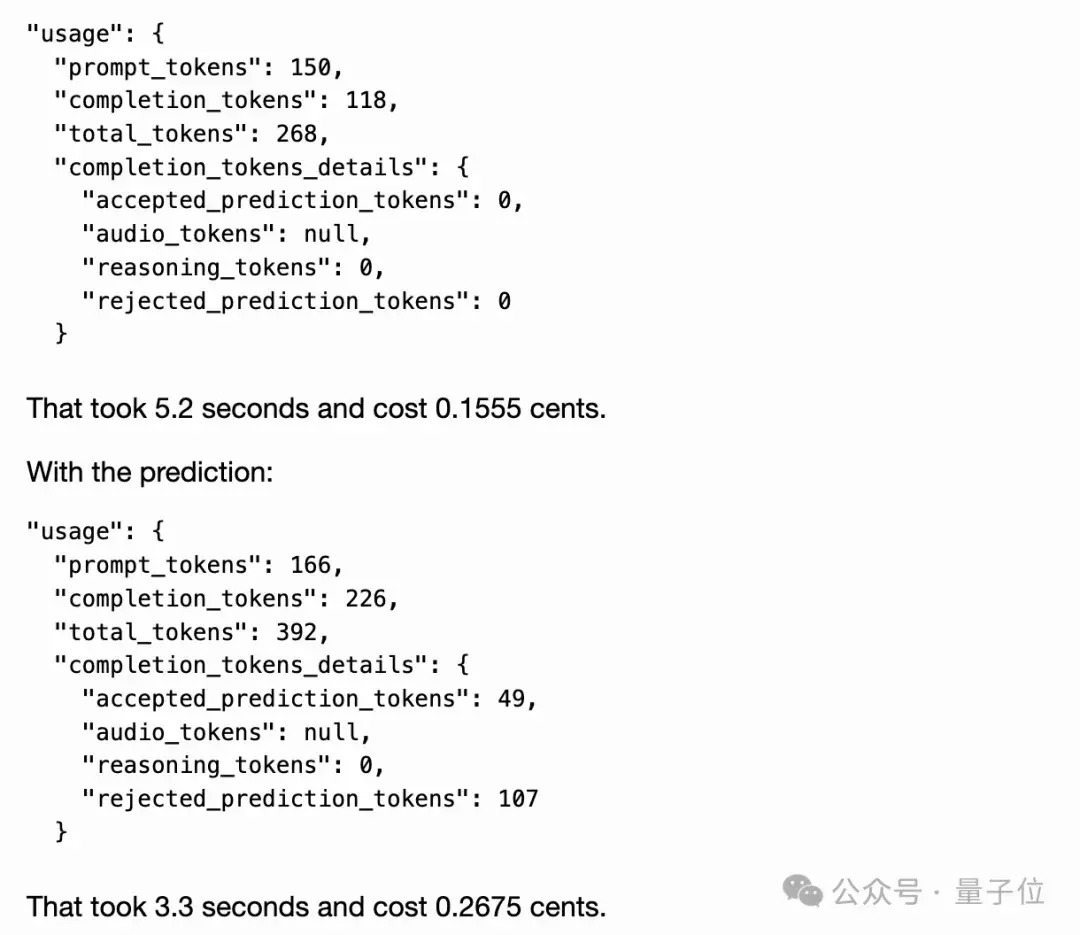
嗯,快了,也贵了。

OpenAI官方文档:
https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outputs参考辘集:
[1]https://x.com/OpenAIDevs/status/1853564730872607229[2]https://x.com/romainhuet/status/1853586848641433834[3]https://x.com/GregKamradt/status/1853620167655481411— 完 —
量子位 QbitAI · 头条号签约
情愫咱们,第一时候获知前沿科技动态