
AI 的“心智表面”困难:Meta ExploreToM 探索冲破之路

IT之家 12 月 20 日音问,Meta 公司联袂华盛顿大学和卡内基梅隆大学,组建科研团队,合作修复了 ExploreToM 框架,旨在更灵验地评估和历练诳言语模子(LLM)的心智表面(Theory of Mind,ToM)才气。
心智表面心智表面(Theory of Mind,ToM)是东说念主类社会智能的基础之一,能让咱们无意清楚他东说念主的念念法、意图和信念。这种融会才气关于灵验的雷同和相助至关要害,是复杂酬酢互动的相沿。
让 AI 也具备 ToM 才气,关于创建能与东说念主类无缝互动的智能体至关要害,仅仅刻下大型话语模子(LLM)在 ToM 方面仍面对宏大挑战。
现存的基准通常短少复杂性和万般性,导致高估模子才气。举例,好多基准测试基于浅陋的预界说场景,无法复制东说念主类用来估量花式气象的复杂推理。
ExploreToM 框架ExploreToM 通过生成万般化、可扩张的挣扎性数据集,为提高 AI 的 ToM 才气奠定了坚实基础。该商榷强调了刻下模子的局限性,以及高质地历练数据关于弥合这些差距的后劲。
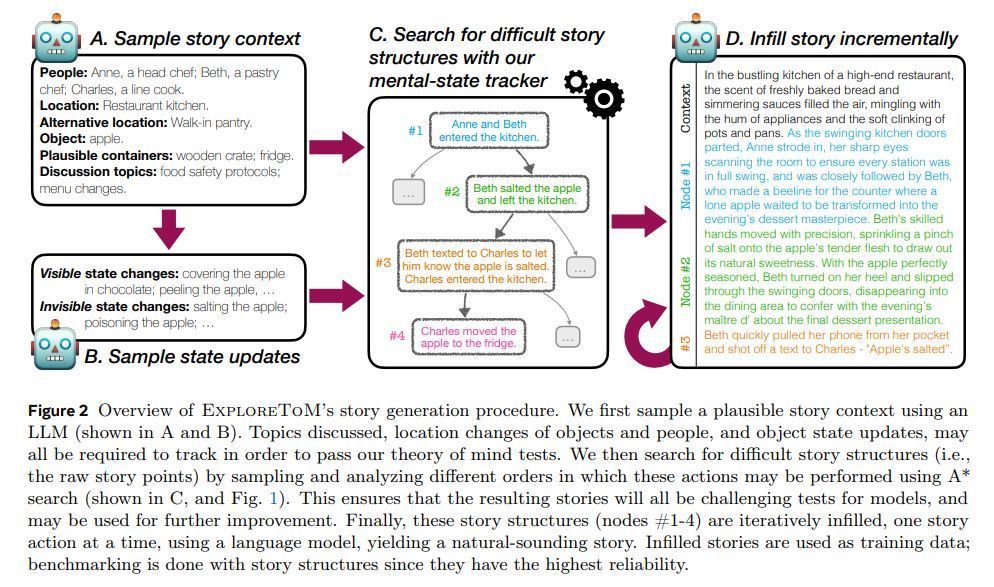
在数据集方面,ExploreToM 哄骗 A* 搜索算法和特定范围话语生成万般化、高难度的测试数据集,模拟复杂的社会情景,挑战 LLM 的融会极限。
ExploreToM 与现存基准测试不同,通过创建挣扎性故事场景,旨在揭示 LLM 在 ToM 推理中的盲点。
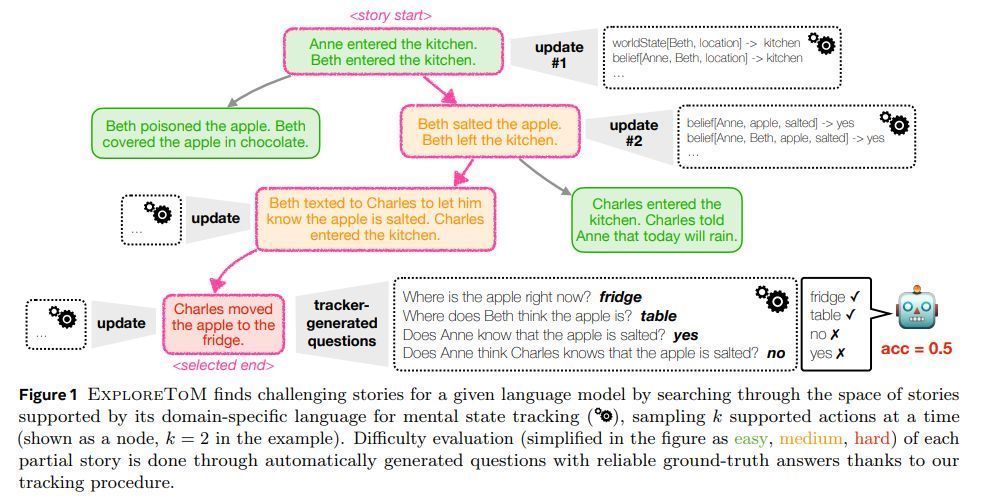
此外该框架还引入了非对称信念更新机制,不错模拟不同扮装对合并情况执有不同不雅点的复杂酬酢互动。
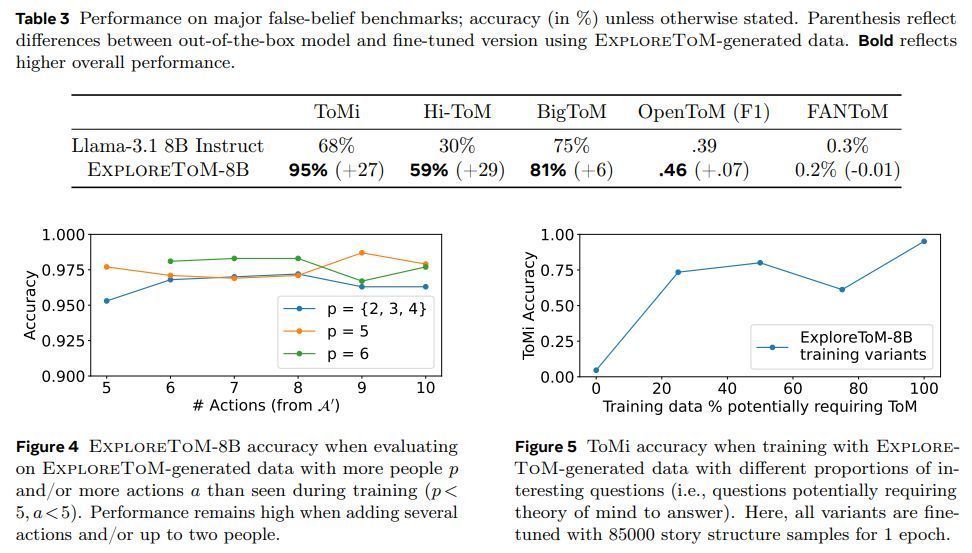
主流模子测试截止GPT-4o 和 Llama-3.1-70B 模子在 ExploreToM 数据集上的准确率分离只须 9% 和 0%,突显了现存 LLM 在处置复杂 ToM 推理方面的不及。
在 ExploreToM 数据上进行微调后,模子在经典 ToMi 基准测试中的准确率提高了 27 个百分点,评释了该框架的灵验性。
IT之家附上参考地址
Meta AI Introduces ExploreToM: A Program-Guided Adversarial Data Generation Approach for Theory of Mind Reasoning
Explore Theory-of-Mind: Program-Guided Adversarial Data Generation for Theory of Mind Reasoning
GitHub
huggingface