
字节开源全栈AI编程基准,不谨防曝光豆包代码大模子

允中 发自 凹非寺
量子位 | 公众号 QbitAI
豆包代码大模子,不谨防给曝光了!
在字节开源的代码大模子评估基准FullStack Bench内部,出现了此前字节未裸露过的Doubao-Coder。
不外目下还仅仅Preview版,还并莫得上线。
它在多种编程话语上的性能阐扬如下,可以看到在闭源模子中名依次五。
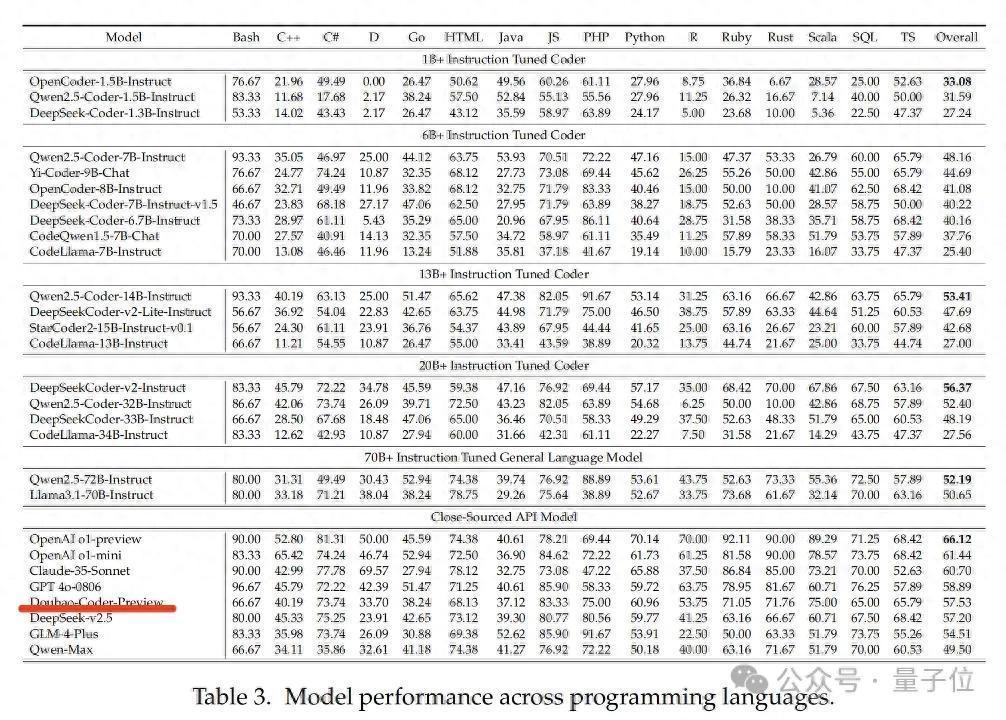
本年6月,字节还发布了AI编程助手豆包MarsCode。据传即由Doubao-Coder模子扶植。
目下,豆包MarsCode每月为用户孝敬百万量级代码。
而回到这个评估基准,据先容FullStack Bench是目下最全面的代码评估数据集。
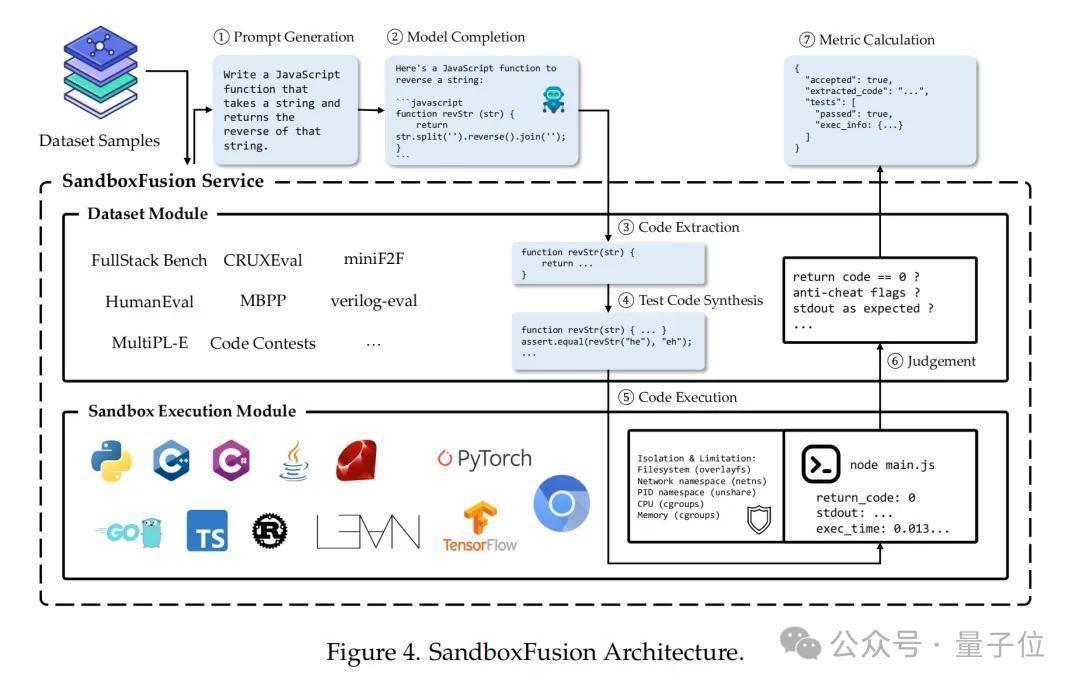
团队还同步开源了可随时测评代码大模子的沙盒实践环境SandBox Fusion,单处事器即可部署,也可平直在线体验。
全新代码大模子评估基准FullStack Bench既然如斯,那就先来了解一下这个最新评估基准。
有一说一,目下代码大模子越来越卷,评估AI编程水平的“考卷”也被动升级~
代码评估基准可以匡助代码大模子延续优化。不外,刻下的主流基准越来越难以反应代码大模子的真实水平了。
主要体目下题目类型相对单调,销亡的应用领域和编程话语少,模子即便在进修中拿了高分,实践中可能也曾难以冒失复杂的编程问题。
为了更真实地评估AI编程水平,字节豆包大模子团队贯串M-A-P社区,开源了全新代码大模子评估基准FullStack Bench。

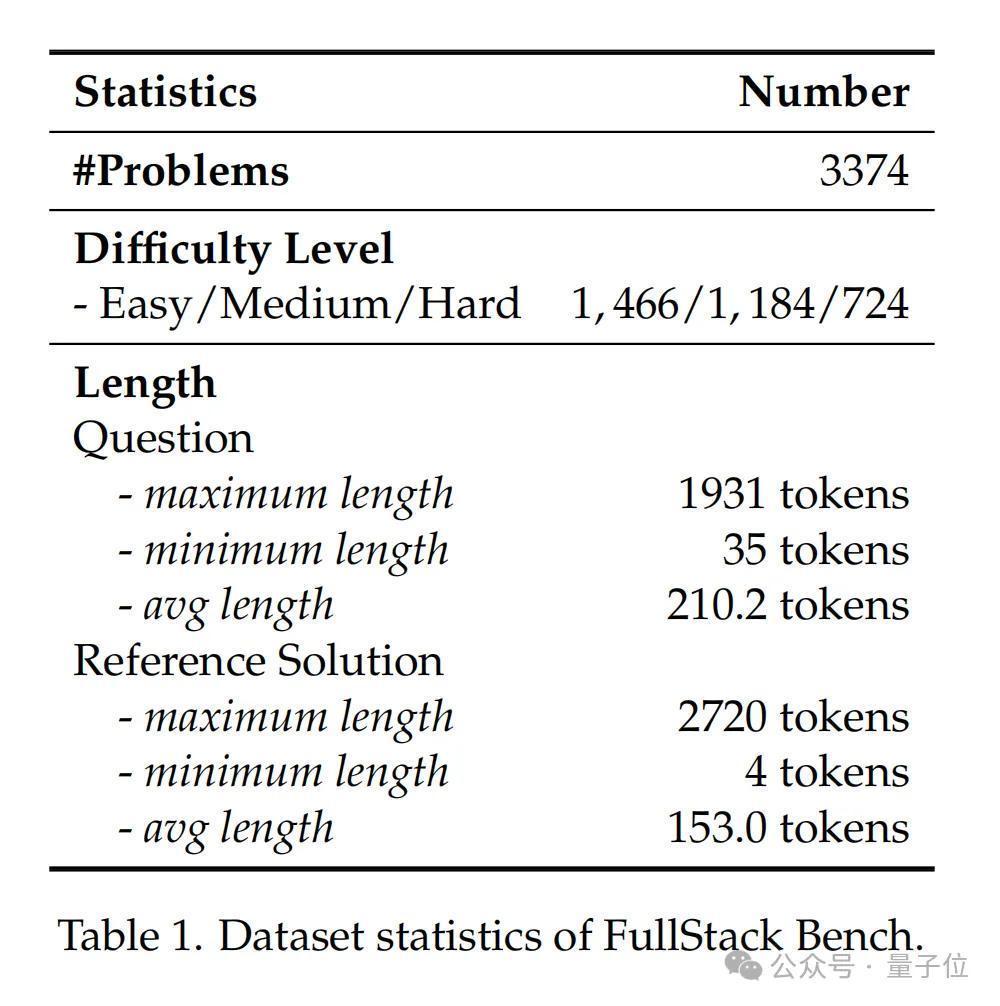
这是一个专注于全栈编程和多话语编程的代码评估数据集,它初度囊括了编程全栈时代中进步11类真实场景,销亡16种编程话语,包含3374个问题。
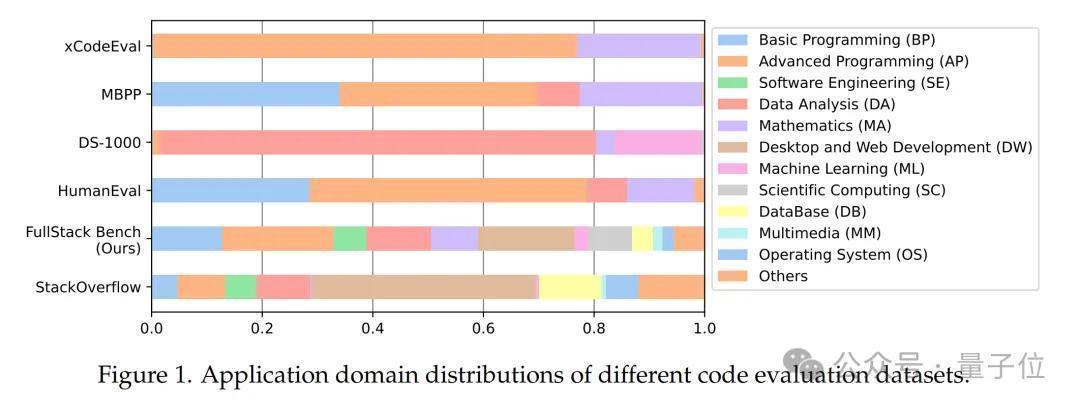
FullStack Bench的应用领域抽取自环球最大的设施员时代问答社区Stack Overflow,比拟HumanEval等基准销亡的编程领域扩大了一倍以上。
此前业界基准难以反应真实宇宙代码确立的各样性和复杂性。
举例,HumanEval和MBPP中近80%数据只聚焦于基础编程和高档编程问题;DS-1000中进步95%数据辘集于数据分析和机器学习,且仅对Python话语进行评测;xCodeEval虽销亡多项任务,但基本局限于高档编程和数学领域;McEval和MDEval扩张了支捏的编程话语,但应用领域仍局限于基础编程和高档编程,未波及更浅近的场景。
为模拟全栈确立的骨子应用场景,字节豆包大模子和M-A-P接洽团队分析了环球最大的设施员时代问答社区Stack Overflow上的问题散布,从中索取出常见的真实编程应用领域。
团队从Stack Overflow受骗场抽取了50万个问题,并使用大模子为每个问题标注应用领域类型。
接洽团队筛选出占总问题数前88.1%的主要应用领域,其余领域归类为“其他”。再通过对领域散布作念允洽调遣来保证鲁棒性,最终酿成了FullStack Bench温雅的进步11种应用场景及散布比例。
FullStack Bench包含3374个问题(中语及英文问题各占一半),每个问题均包括题目描写、参考惩处决策、单位测试用例及标签,筹画15168个单位测试。
为保证评估准确性,每个问题内容均由研究领域的编程民众推敲,并经AI和东谈主工考据进行质料复核。举例,数据分析研究问题,由数据工程民众漠视并把关配套内容。
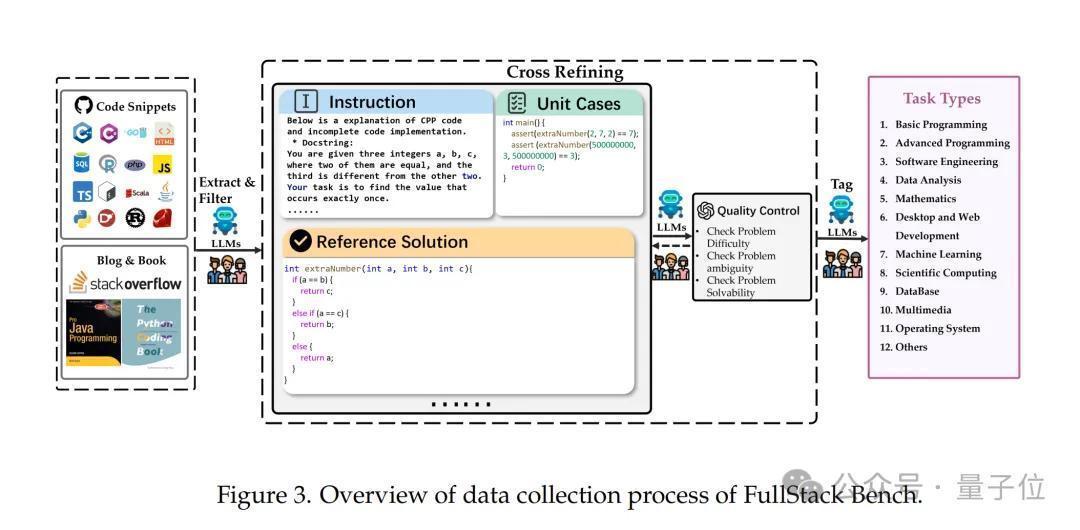
在启动数据集构建后,团队左证主流代码大模子测试成果,按问题难度、磨蹭性和可解性对数据质料进行了交叉评估和进一步完善。
FullStack Bench数据组成情况如下图所示。
为便捷确立者对大模子代码智商进行系统性测试,豆包大模子团队还开源了一款高效的代码沙盒实践器具——SandboxFusion,用于评估来自不同话语的不同编程任务。
除了FullStack Bench,SandboxFusion还兼容进步10种浅近使用的代码评估数据集,支捏23种编程话语。确立者在单处事器上即可狂妄部署SandboxFusion,也可平直在GitHub上进行体验。
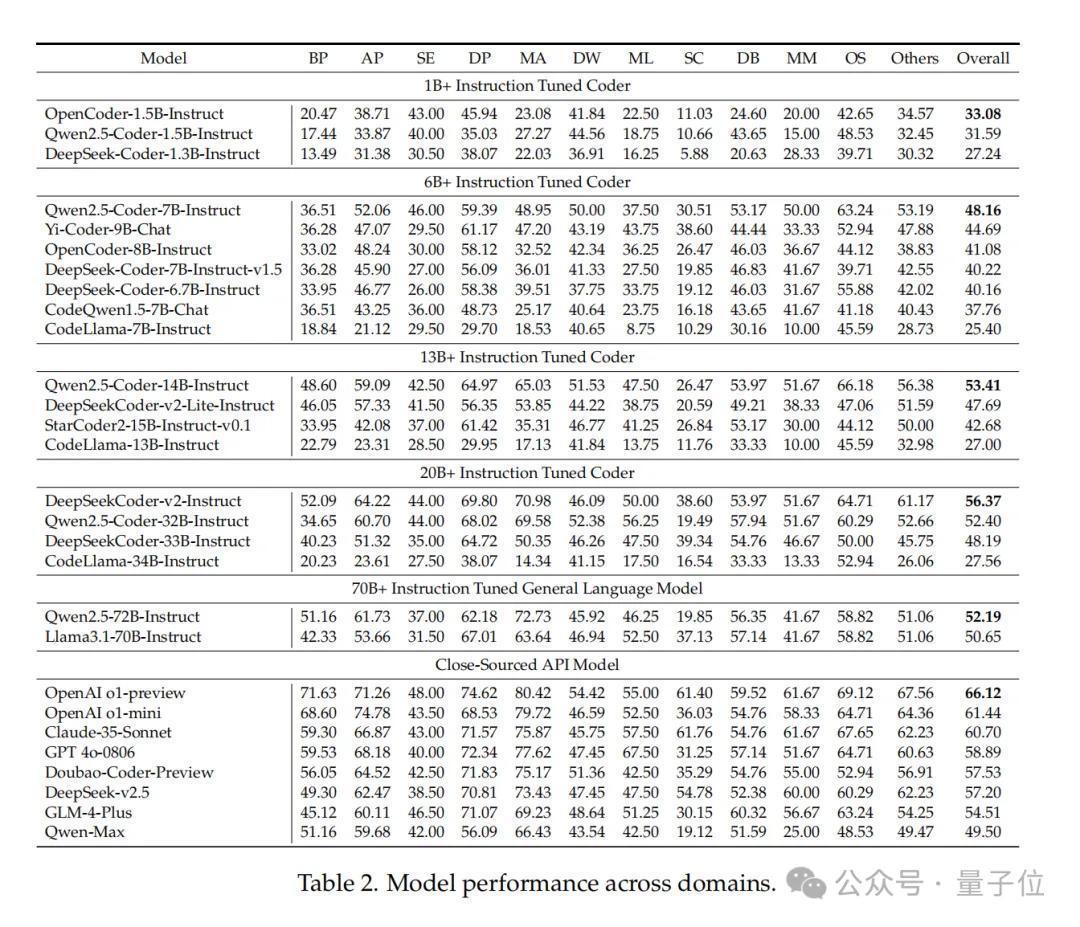
评测成果:惩处费劲,闭源模子仍优于开源模子
发布评测基准及沙盒的同期,接洽团队也基于FullStack Bench测评了环球20余款代码大模子及话语大模子的编程阐扬。
模子包括Qwen2.5-Coder、DeepSeek-Coder-v2、CodeLlama等开源模子,以及GPT-4o、OpenAI-o1、Doubao-Coder-Preview等闭源模子。关于开源模子,左证模子大小,分为五个组别:1B+、6B+、13B+、20B+和70B+。
跨领域阐扬:数学编程领域各异最大
收货于广阔的推贤达商,OpenAI o1-preview竟然如斯地起首。
不外,一些开源模子也有可以的阐扬。如DeepSeekCoderv2-Instruct,在AP(高档编程)、OS(操作系统)和其他类别中得到高分,拉开了与其他开源模子的差距。
OpenCoder-1.5B-Instruct、Qwen2.5-Coder-7B-Instruct、Qwen2.5-Coder-14B-Instruct在其各自开源组别中拔得头筹,并卓越了一些更高参数级别的模子。
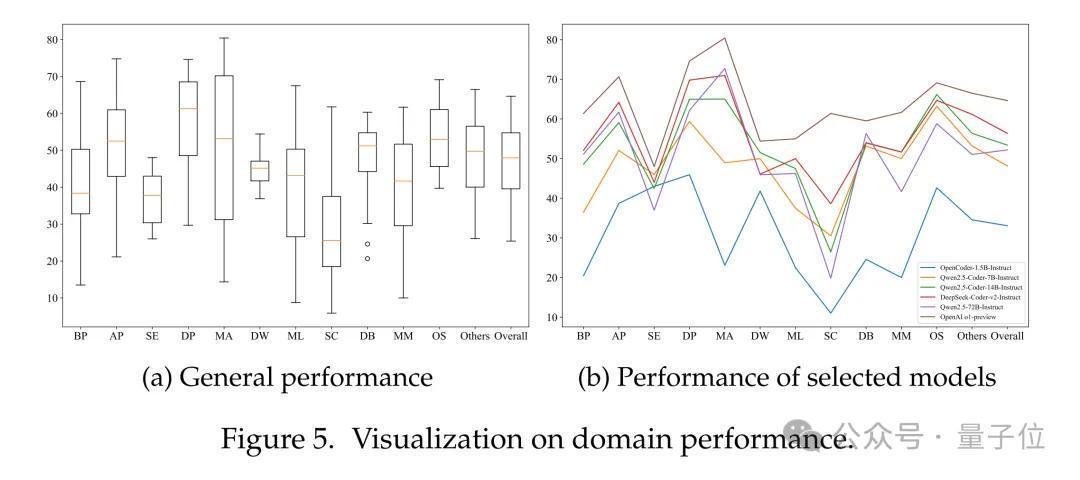
为了全面评估现有妄语语模子在不同场景下的阐扬,接洽团队可视化了模子在FullStack Bench各领域的阐扬。
在BP(基础编程)、AP(高档编程)、MA(数学编程)、ML(机器学习)和MM(多媒体)等领域中,模子阐扬各异权臣,其中以MA领域的差距最大。
MA最好阐扬者为OpenAI o1-preview(得分80.42),而最差的是CodeLlama-34B-Instruct(得分14.34)。数学编程条目模子同期具备数学和编程智商,那些在高度专科化代码语料库上进修的模子,在MA领域经常阐扬较差。
这一成果进一步阐扬,FullStack Bench或者更全面地评估模子的笼统编程智商。
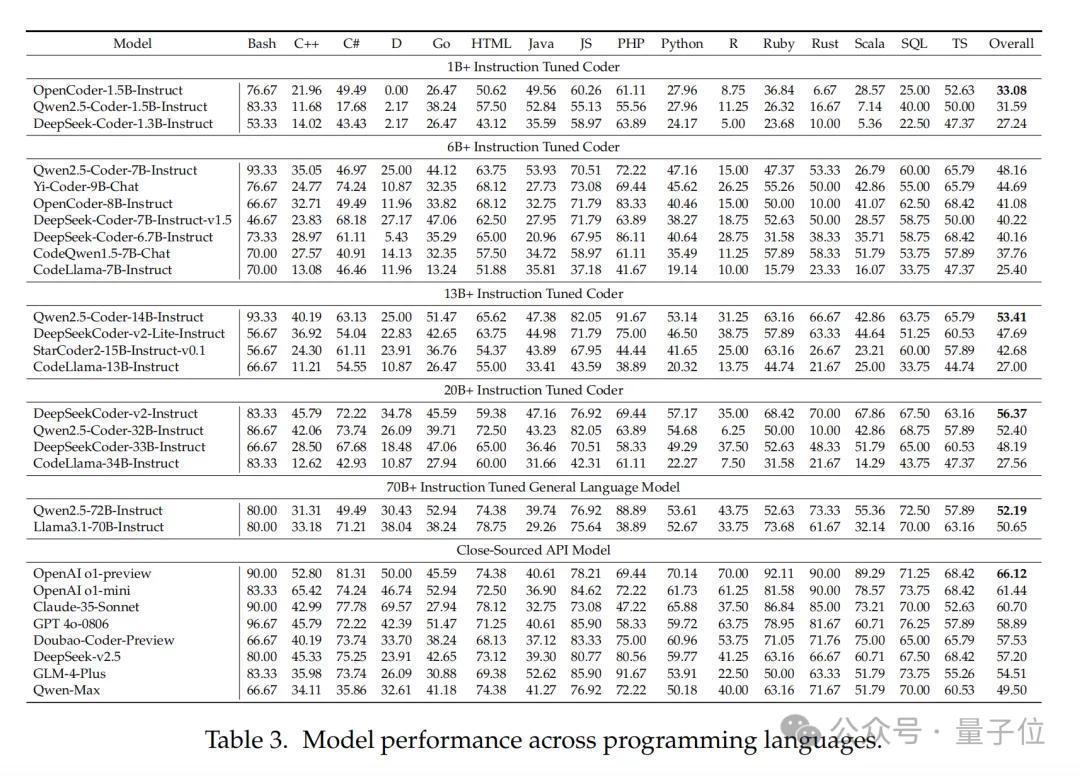
跨话语阐扬:C++、C和Ruby上存较大各异
接洽团队对不同模子在多种编程话语上的性能阐扬进行了分析。
大大批模子在Bash编程任务中阐扬细密。可是,在C++、C和Ruby的阐扬上存在较大各异,这标明模子推敲者可能在进修语料库中对这些话语进行了遴荐性采样。部分1B+的微型模子在D、R和Scala话语上的阐扬较差,其通过率低于10%,这标明它们的多话语处贤达商皆较弱。
由于SandboxFusion提供了来自编译器的反馈,接洽东谈主员评估了模子在部分编程话语上的编译通过率。实验成果标明,编译通过率与测试通过率之间存在正研究关连,但编译通过并不虞味着测试一定通过。同期,接洽还探讨了中英文抒发对模子性能的影响。
惩处费劲,闭源模子精深优于开源模子
不同模子在不同难度问题上的阐扬有在较着各异。总体而言,1B+模子和CodeLlama系列在总计难度级别上的阐扬均不尽如东谈认识。其余模子在惩处苟简问题时阐扬雷同,但在中等难度问题上存在一定差距。关于难度较大的问题,闭源模子精深优于开源模子。
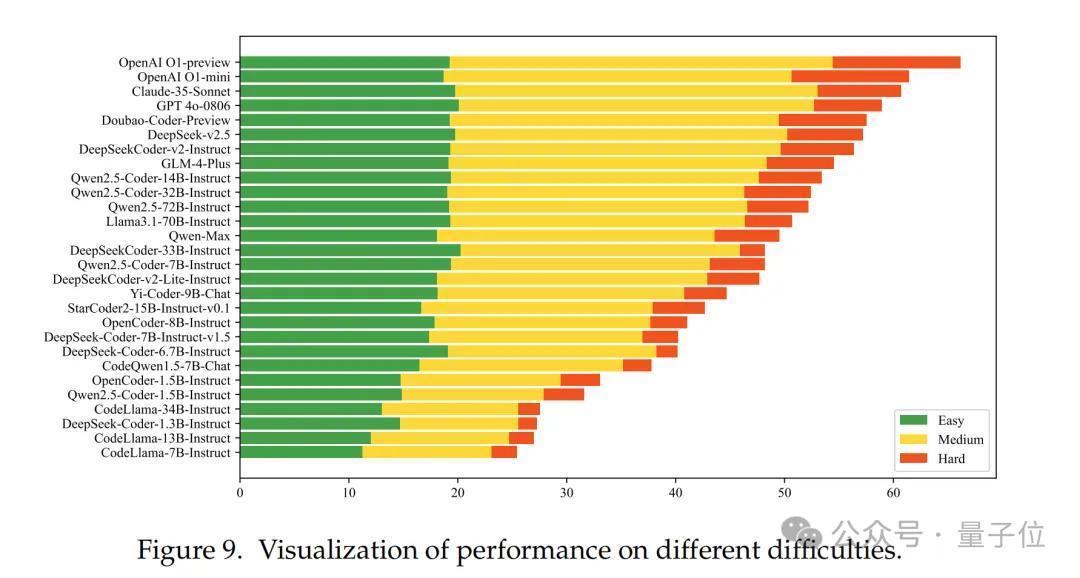
使用SandboxFusion,可进步模子阐扬
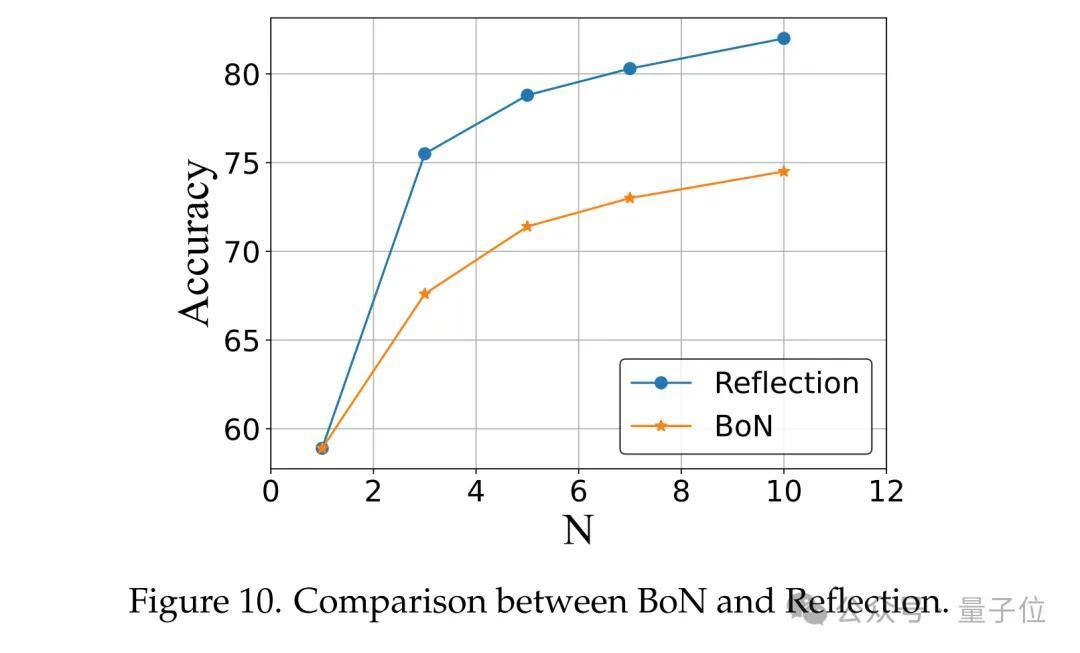
接洽东谈主员对比了“反想政策(Reflection)”和“N次想到政策(BoN)”两种政策。在Reflection政策中,通过欺诈SandboxFusion的反馈高下文对谜底进行N次细密,复现了自我细密政策 [Madaan et al., 2024]。而在BoN政策中,仅进行N次想到以得到成果。
成果如图所示,“Reflection”政策较着优于“BoN”,这标明SandboxFusion提供的反馈高下文具有较高的有用性。
了解这篇接洽果然定,可见文内Arxiv趋附,或温雅「豆包大模子团队」公众号,查阅更注释解读。
参考趋附:[1]论文趋附:https://arxiv.org/pdf/2412.00535v2[2]数据集开源地址:https://huggingface.co/datasets/ByteDance/FullStackBench[3]沙盒开源地址:https://github.com/bytedance/SandboxFusion[4]沙盒体验进口:https://bytedance.github.io/SandboxFusion/playground/datasets
— 完 —
量子位 QbitAI · 头条号签
温雅咱们,第一时候获知前沿科技动态约